Faptul că BigData e un subiect la modă este confirmat și în numărul curent al TSM în care se scrie despre acest subiect. Introducerea în BigData și conceptele specifice a fost făcută în numerele 2, 3 și 4 ale revistei. Pentru a rezuma, BigData înseamnă stocarea și analiza volumelor de date mari, începând cu ordinul Terra Bytes. Gestionarea unor astfel de volume de date ridică problema celor 3V în ceea ce privește Volumul, Viteza de acces și Varietatea datelor.
Teorema CAP formalizează constrângerile acestor sisteme: Consistency, Availability și Partition Tolerance.
Consistency se referă la consistența datelor din punctul de vedere al clienților sistemului. Altfel spus toți clienții văd aceleași date, tot timpul.
Availability este o garanție că fiecare request va primi un răspuns.
Partition tolerance este proprietatea sistemului de a funcționa atunci când noduri din sistem cad.
Conform teoremei CAP un sistem nu poate satisface simultan toate cele 3 constrângeri, dar poate excela la oricare 2 din ele. În scopul de a ne încadra în acelaşi trend și de-a împărtăși comunității din experiența practică acumulată pe proiectele interne, vă supunem atenției un studiu de caz cu 4 dintre cele mai populare soluții NoSQL: Riak, Couchbase, Hypertable si Cassandra.
Unul din clienţii importanţi ai companiei se confruntă cu o problemă tehnică - are un volum imens de date pe care nu le mai poate gestiona. Are nevoie de o soluție NoSQL. Există deja modelul de date: un compozit de POJO1 -uri.
Luăm ca exemplu al modelului de date un articol cu reprezentarea UML:

Ca și cerințe vrem să:
Totodată mai vrem ca datele să aibă un nivel acceptabil de consistență și sa fie available.
Maparea modelului de date mai sus menționat, care va fi rafinată ulterior, este specifică în funcție de strategia de stocare pe disc a fiecărei baze de date NoSQL.
Bazele de date din categoria Key-Value precum Riak sunt conceptual dicţionare distribuite și nu au o schema predefinită, sunt schemaless. Cheia poate fi sintetică sau auto-generată, iar valoarea poate fi orice: String, JSON, BLOB etc.
Un alt concept specific unor storage-uri Key-Value este bucketul: o grupare logica pentru mai multe chei-valori, nu grupează fizic datele în același loc pe disc. Pot exista keys identice (cu valori diferite) în bucketuri diferite.
Pentru a citi o valoare este necesară cunoașterea cheii și a bucketului, deoarece adevărata cheie sub care se păstrează valoarea este hash(Key + Bucket).
Ca și raportare la teorema CAP, bazele de date Key-Value excelează la A și P dar sacrifică C într-o masură acceptabilă - garantează eventually consistency: "mai bine îți ofer (pe unele noduri) date vechi, dar rapid și îți garantez că datele nou inserate vor fi consistente pe toate nodurile cândva în viitor".
Couchbase si MongoDB sunt cele mai populare baze de date de tip document based. Sunt flexibile la tipul conținutului fiindcă nu au o schema predefinită. Conceptual lucrează cu documente de diferite forme: JSON, BSON, XML dar și BLOBs de tip PDF, XLS.
În esentă nu sunt decât o specializare a bazelor de date Key-Value. Un document se scrie/citește folosind o cheie. Pe langă functionalitatea Key-Value, bazele de date tip document adaugă funcționalități de găsire a documentelor bazat pe conținutul acestora. Raportat la teorema CAP, bazele de date orientate document excelează la C și P.
Bazele de date din categoria BigTable2 precum HBase3 si Hypertable4 sunt de tip columnar și au o schemă ce trebuie predefinită.
Datele sunt stocate în celule grupate pe coloane. Coloanele sunt grupate logic în column families. Acestea pot contine un număr teoretic nelimitat (limitat în funcție de implementarea specifică) de coloane ce pot fi create la runtime sau la definirea schemei.
Vă puteți întreba: ce beneficiu am dacă stochez datele în coloane și nu în rows, așa cum fac bazele de date relaționale ?
Răspuns scurt: Timp redus de căutare/acces și agregare a datelor.
Răspuns lung simplificat: Bazele de date relaționale stochează pe disc într-o zonă continuă un singur row dintr-o tabelă. Diferite row-uri dintr-o tabelă sunt stocate în locații diferite pe disc.
Bazele de date columnare stochează pe disc într-o zona continuă toate celulele corespunzătoare tuturor row-urilor dintr-o coloană.

Pentru o înţelegere mai bună propunem următorul caz de utilizare simplificat (fără indecși, cache etc.):
Am 1 miliard de articole și vreau titlul tuturor articolelor. Bazele de date relaţionale iterează peste locații diferite de disc pentru a colecta titlul fiecărui articol. Rezulta 1 miliard de iteraţii și accese la disc.
Bazele de date columnare ar necesita un singur acces la disc pentru că titlurile tuturor articolelor sunt într-o locație continuă pe disc, în coloana Title. Prin extrapolare în condiții reale, rezultă un număr dramatic scăzut de iteraţii pentru bazele de date columnare. Ca și raportare la teorema CAP, bazele de date columnare satisfac C și P dar sacrifică A.
Riak5 este un Key-Value store distribuit, open-source cu suport enterprise, dezvoltat de Basho Technologies. Este proiectat sa scaleze orizontal și să fie rezilient.
Riak consideră toate nodurile din cluster egale, fără master, deci nu are Single Point Of Failure. Fiindcă excelează la availability, scalability, este tolerant la partitia retelei și asigură replicarea datelor în 3 locații, se laudă a fi cel mai rezilient storage Key-Value pus în producție. Pentru garantarea acestor caracteristici, Riak oferă un nivel de consistență eventuală.
Rezolvarea conflictelor de date este rezolvată cu ajutorul vector clock (ceas logic).
Riak vine cu un mecanism de pluggable storage: poți alege între Bitcask6 - toate cheile în RAM sau LevelDB7 - toate cheile și valorile pe disk, dar oferă un API ce permite implementarea propriului storage. În funcție de environmentul în care se face deployment se poate face o alegere pentru optimizarea costurilor de producție.
Toate nodurile dintr-un cluster comunică prin protocolul Gossip8 de unde rezultă trafic pe rețea deloc neglijabil. Acest protocol de tip viral asigura monitorizarea permanentă a disponibilității clusterului și replicarea datelor.
Datele sunt stocate în tuple Key-Value într-un bucket. Valorile pot fi orice: text, JSON, XML, BLOB etc.
În cazul modelului de date anterior amintit (vezi diagrama de la Context și cerințe), mai jos este reprezentarea JSON a articolului cu cheia: "123"
{ article: id: 123, title: "Article title", content: "This is the content",
location: { country: "Romania", latitude:123.45, longitude:123.45}
tags: [
{ name: "tag1", date: "10 Mar 1981", author:"John B"},
{ name: "tag2", date: "21 Mar 1981", author:"John B"}
],
}Se instalează foarte ușor atât local cât și în cluster. În cluster nodurile se adaugă într-o zona de staging și pot fi activate prin mutarea în zona commit. Pentru monitorizare se instalează Riak Control.
Cele 2 fisiere vm.args și app.config cuprind toate aspectele configurării: securitate, cluster tuning etc.
Sharding-ul automat functionează, dar atenţie sporită la ring size si la numărul de vnodes care trebuie din start corect configurate, altfel trebuie reconfigurat clusterul și poate fi necesară chiar reimportarea tuturor datelor.
Pentru majoritatea limbajelor există clienți care comunică prin Protobuf sau REST. Deși au o interfaţă comună, implementarea REST oferă mai multe funcționalități față de Protobuf în defavoarea vitezei de comunicare. REST oferă în plus și posibilitatea pentru query-uri ne-complexe de Map Reduce. Folosind Bitcask am avut neplăceri la listarea cheilor dintr-un bucket in environment de producție.
În cloud, Riak comunică prin Gossip și cu alte clustere - care nu aparțin neapărat companiei, deci riscăm data leaks.
Couchbase9 este un storage de documente JSON. Își are rădăcinile în CouchDB10 , proiect aflat sub umbrela Apache. Compania CouchOne Inc., ce oferea suport comercial pentru CouchDB, împreună cu Membase Inc. au format Couchbase Inc. Noua soluție, Couchbase, combină modelul de date, indexarea și capabilitățile de interogare CouchDB cu performanța și scalabilitatea Membase.
Fiind dezvoltat comercial ca proiect open-source este oferit în trei moduri de licențiere: open-source, community și commercial.
Modelul de date este de document JSON, fără relații între documentele stocate în bucket-uri, limitat la 20MB/document. La nivel de cluster datele sunt păstrate în memorie, replicate, fiind consistente și salvate asincron pe disc. Între clustere diferite datele sunt eventually-consistent.Accesul la date se poate face direct, bazat pe cheie, prin Map-Reduce, prin limbajul de interogare UnQL11 sau prin integrare cu Hadoop12.
Modelarea datelor este identică cu cea pentru Riak.
Unul dintre capitolele la care excelează Couchbase este instalarea. Astfel instalarea pe un cluster se poate realiza în doar câteva minute. De asemnea mai beneficiază și de unelte de monitorizare integrate în instalarea implicită.
Configurarea este deosebit de rapidă, chiar și în mod distribuit. Singura bilă neagră ce o primește Couchbase este dată de limitarea de a avea sisteme eterogene din punct de vedere al memoriei RAM folosite. Această limitare nu permite exploatarea la maxim a memoriei disponibile pe fiecare dintre noduri.
API-ul de Java oferă o interfață simplă și intuitivă astfel încât se poate scrie cod în doar câteva minute. Documentația este de asemenea suficientă și fără erori.Bazându-se pe stocarea datelor în memorie performanța este foarte bună.
După cum am menţionat, este bazat pe filozofia Google Big Table si concurează cu HBase. Printr-un API generic, suportă diverse sisteme de fișiere distribuite, cel mai utilizat fiind HDFS - Hadoop Distributed File System13. HDFS este sistemul distribuit de fişiere oferit de Hadoop si inspirat din Google File System14. Hadoop este un proiect open-source dezvoltat iniţial de Yahoo! pentru procesarea distribuită a volumelor mari de date. Varianta curentă de Hadoop conține un ecosistem de diverse module cu suport de la query ad-hoc pană la data mining și machine learning.
Termenii specifici bazelor de date columnare și corespondența cu bazele de date relaționale sunt:
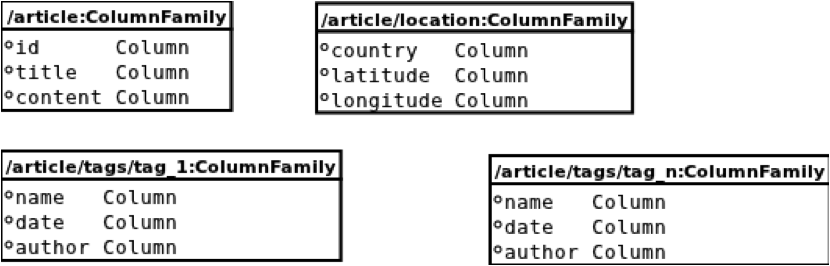
Maparea modelului compozit de date descrise în paragraful "Context și cerințe" s-a făcut astfel:
Fiecare POJO din model, (dar nu instanță) are asociat câte un column-family.
Fiecare membru atomic al acelui POJO care poate fi reprezentat ca text are asociată o coloană din același column-family. Membrii compuși au fost la rândul lor modelați ca un column-family diferit.
Având ca intrare urmatorul articol, reprezentat ca JSON:
{ article:
{ id: 123, title: "Article title", content: "This is the content",
location: { country: "Romania", latitude: 123.45, longitude: 123.45}
tags:[
{ name: "Cool", date: "10 Mar 1981", author: "John B"},
{ name: "TSM", date: "21 Mar 1981", author:"John B"}
],
}Am generat următoarea structură de coloane:
Am ales această structură de reprezentare deoarece oferă posibilitatea de a căuta rapid după orice proprietate a obiectului.
Local se instalează uşor, iar pe un cluster o mare parte a instalării se poate automatiza, dar este de o complexitate medie fiindcă sistemul distribuit de fişiere, HDFS trebuie configurat și pornit separat.
Se face pe fiecare nod în parte, de asemenea automatizată. Există un set satisfăcător de opțiuni de configurare, dar semnificația acestor opțiuni nu este suficient documentată.
Exista clienţi pentru limbajele populare de programare: Java, PHP, Python etc. Comunicarea clienţilor cu Hypertable se face prin protocolul Thrift.
Deşi comunitatea este restrânsă, suportul este bun. Se vede influenţa adâncă a limbajului C de la interfaţa low level a clientului, pană la API și la mesajele de eroare. În urma testelor efectuate am observat ca este mai lent la heavy inserts decat Cassandra, Riak și CouchBase.
În versiunea curentă, Hypertable este limitat la un număr maxim de 255 de column families deci te forţează să-ți faci un design bun la schema; flexibil pentru extensii ulterioare. Din motive practice (stabilitate, knowledge base, work-arounds), versiunea 0.20 de Hadoop este preponderent folosită, în defavoarea versiunii curente. Folosiţi distribuţia Hadoop de la Cloudera15 pentru a va face viaţa mai uşoară: instalarea, configurarea simplificată și documentația mai bună.
Cassandra16 a porinit ca un proiect open-source de la Facebook, ajuns sub umbrela Apache. Implementarea îmbină concepte din Amazon Dynamo17 și Google BigTable. Poate fi caracterizat ca un key-value store eventually consistent.
La fel ca Riak și Cassandra pornește de la conceptele publicate de Amazon în lucrarea ce descrie Dynamo. Această lucrare prezintă designul și implementarea aleasă de Amazon pentru a crea DynamoDB18, o baza de date highly available, ce stochează datele în format Key-Value.
Plecând de la Dynamo, Cassandra a renunțat la vector-clocks pentru rezolvarea conflictelor și a implementat o strategie diferită de stocare ce se bazează pe ColumnFamily.
Se integrează și cu Hadoop, putând distribui sarcinile pe grupuri diferite de mașini. În acest mod putem realiza două partiții - una rulând sarcini în timp real și cealaltă rulând sarcini de analiză, ce pot consuma mai mult timp.
Adaptarea modelului de date este identică cu cea menţionată la Hypertable.
Strategia de stocare folosită derivă din bazele de date columnare. Conceptele folosite sunt:
Distribuții recomandate pentru instalarea Cassandra sunt oferite de DataStax20. Ca o particularitate negativă Cassandra necesita Oracle Java 1.6, versiune cu end of support în februarie 2013. Instalarea pe un cluster Linux nu pune probleme deosebite.
În ceea ce privește configurarea Cassandra a fost gândit pentru a se mula pe nevoile utilizatorilor. Oferă nivele diferite de setare a consistency level pentru operații de scriere (5 nivele) și citire (3 nivele). Trebuie avută atenție deoarece în configurarea implicită Cassandra nu este adaptată folosirii în cluster datorită setarilor replication factor(RF) și consistency level(CL).
Singura dificultate întâmpinată la configurare a fost legată de crearea ring-ului. Mașinile componente ale clusterului sunt organizate sub forma unui ring, fiecare având alocată o anumită plajă de tokens ce le stochează. În documentația versiunii curente (1.2.0) valoarea maximă a token-ului este incorect documentată.
Pentru început trebuie să știm cum comunicăm cu Cassandra. Protocolul folosit pentru comunicare este Thrift. Pentru a ușura scrierea de aplicații există numeroase librării client21, pentru multe limbaje de programare. Această varietate face luarea unei decizii mai greoaie. În cazul Java există 9 librării pentru versiunea curentă. Merită amintite Hector și Astyanax. Hector este cel mai răspândit client. Astyanax este un fork din Hector, realizat de Netflix, si oferă o interfață simplificată.
Cassandra având o schemă dinamică permite adăugarea la runtime a oricâtor column-families. La crearea unui keyspace, dacă nu specificăm, RF implicit se alege 1. Astfel datele nu sunt replicate iar în cazul căderii unei mașini datele devin indisponibile sau chiar se pierd.
Pentru a nu pierde date trebuie să știm și că odată inserate datele sunt păstrate în memorie și scrise în commitlog, dupa un interval de timp configurabil. Astfel, în cazul unei probleme hardware sau software se pot pierde datele ce nu au fost scrise în commitlog. Spre deosebire de un log obisnuit, commitlog-ul trebuie tratat cu seriozitate deoarece contine date ce nu au ajuns încă să fie scrise în directorul de date, pe disc.
Sistemele NoSQL sunt într-o fază de evoluție naturală, dar sub nici o formă nu înlocuiesc sistemele mature relaționale, ci le complementează. Exită mai multe soluții NoSQL, aparținând unor clase diferite, fiecare adecvată unei anumite probleme. Deşi oferă un avantaj competitiv, nu există soluţie NoSQL perfectă pentru toate scopurile.
Înainte de face o alegere în acest sens trebuie atent analizate și urmărite următoarele aspecte:
de Mircea Mare









